Abstract
Social media platforms like TikTok have become a key source of health information, including for questions from the peripartum period: before, during, and after pregnancy. Inaccurate health information in this setting can have adverse consequences. As Large Language Model (LLM) providers increasingly integrate LLMs into digital platforms to fact-check content, these systems need to be evaluated on real-world multimodal videos.
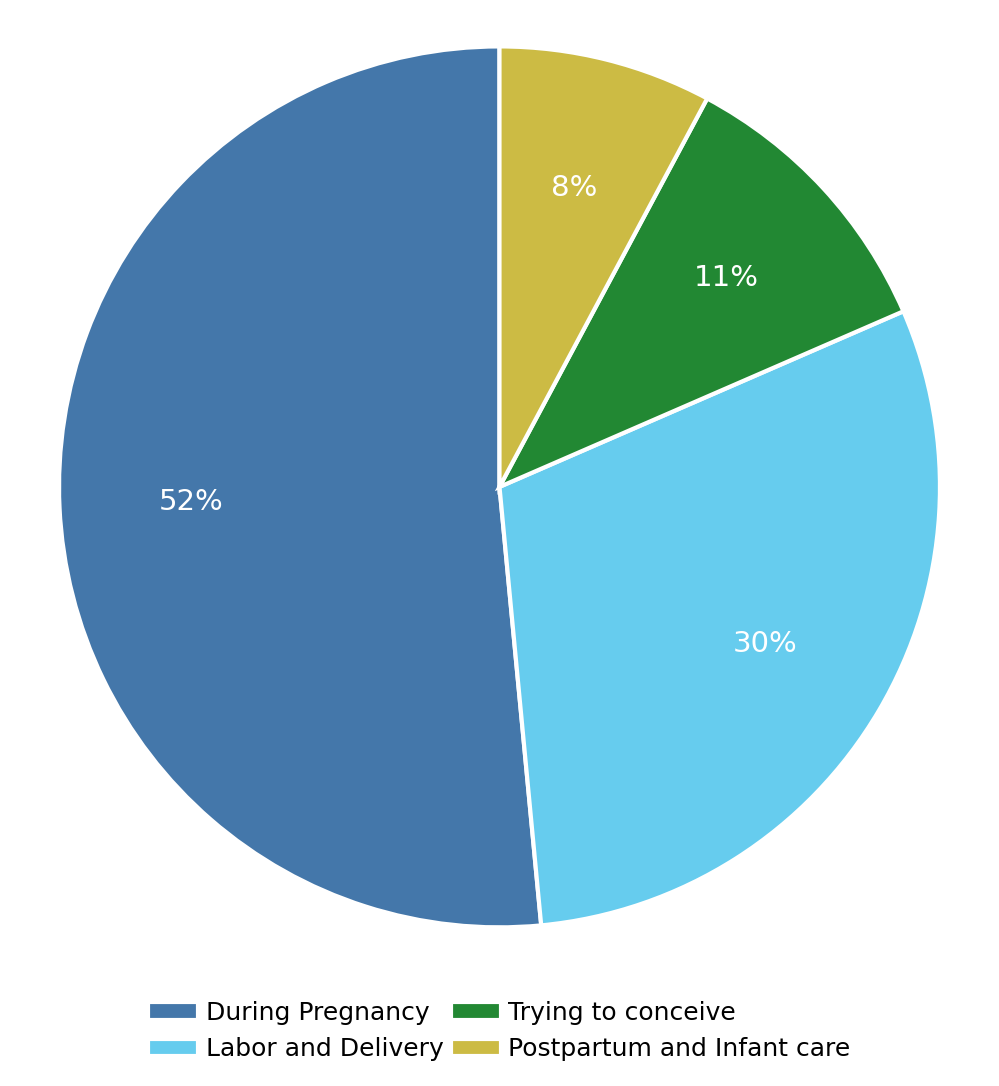
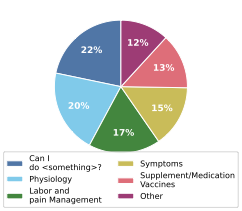
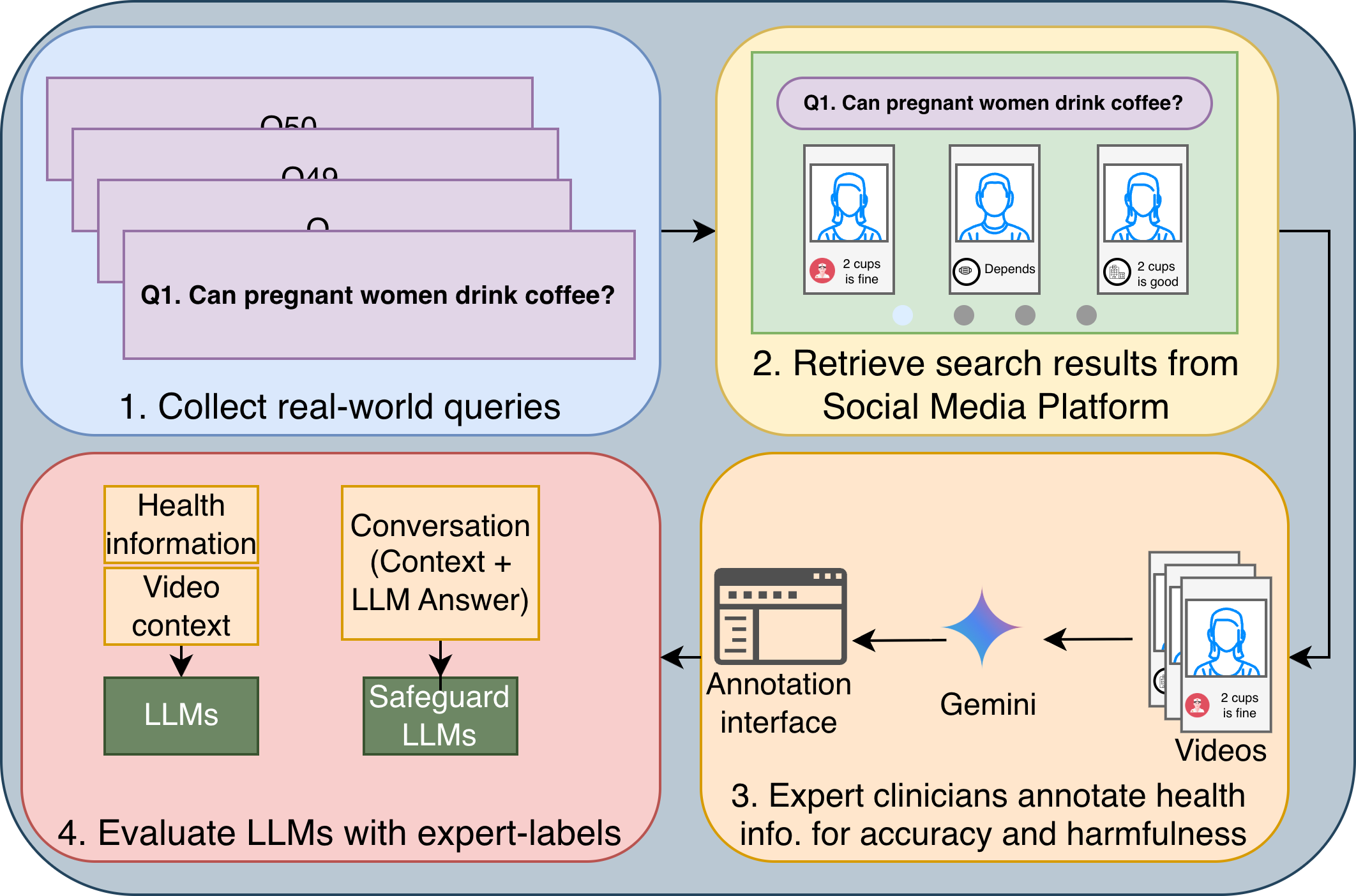
We introduce RELIANCE, an expert-annotated dataset of reproductive health information surfaced by TikTok search. The dataset starts from 56 clinician-reviewed natural-language questions about the peripartum period, collects the top six TikTok video results for each question, and asks expert clinicians to identify medically relevant sentences or paragraphs in the transcripts.
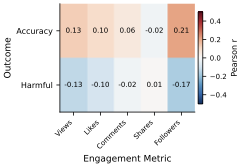
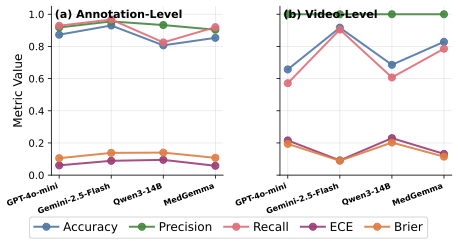
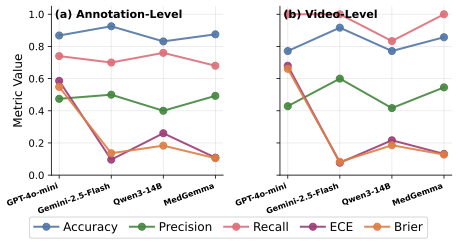
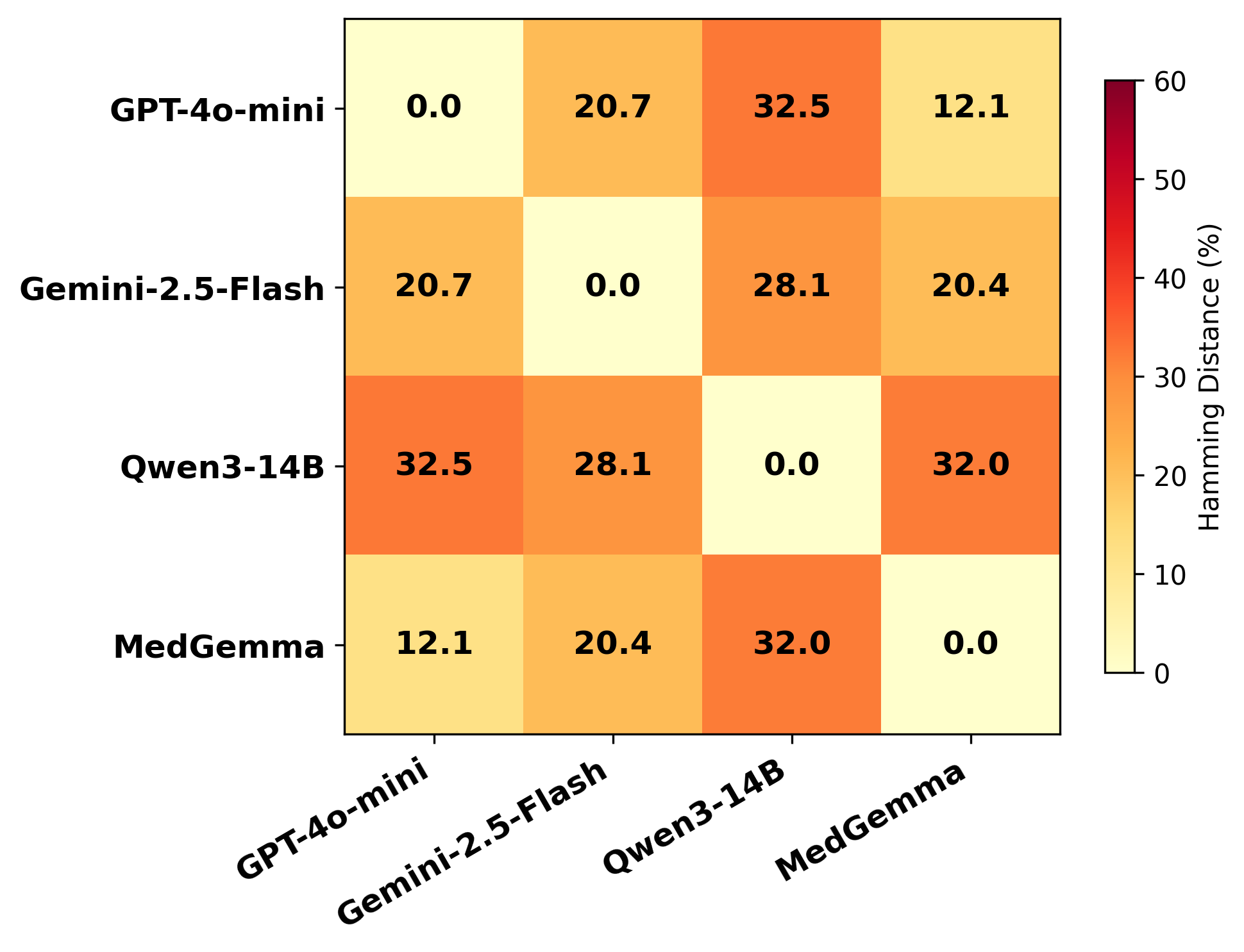
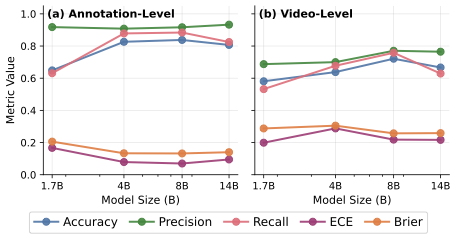
RELIANCE contains 409 annotated sentences or paragraphs from 336 videos. Clinicians label each one for inaccuracy and harmfulness, making it possible to separate information that is not supported by scientific evidence or standard clinical practice from medically dangerous information that can cause adverse consequences. We use the same annotations to evaluate whether LLMs can detect inaccurate and harmful information.